リンク切れチェッカー
Pythonで外部リンクのリンク切れをチェックするコードです。
①パソコン上のホームページファイルを検索し、外部リンクのみを抽出して「list.txt」に出力します。
②「list.txt」の外部リンクのステータスコードをチェックし、「code.txt」に一覧で出力します。
③「code.txt」のリストをエクセルに貼り付け、降順で並べ替えて404などをチェックします。
必要なものがあれば、適宜、pip installしてください。
■①外部リンクのみを抽出して「list.txt」に出力
以下の箇所につきまして、「www.example.com」を自サイトのドメイン名に変更してください。
「if '//' in tag and 'www.example.com' not in tag:」
拡張子「.html」ファイル内の<a hrefタグ内に//があり、かつ自サイトwww.example.comがなければ、内部リンクではなく、外部リンクとしてます。そのため、https://やhttp://だけではなく、省略された//のみの場合でも外部リンクとなります。
加えて、以下の箇所につきまして、パソコン上にある「サイトのフォルダ」を指定してください。
「directory = r'ウェブサイトのフォルダ'」
例えば、デスクトップ上にある場合などは以下のようになります。
「directory = r'C:\Users\user\Desktop\www.example.com'」
ファイルの拡張子は「.html」のみ、文字コードはutf-8のみですが、必要に応じて生成AIなどで修正してください。ファイル名は「sample.py」など、適当なものを使用してください。
import os import re from html import unescape def process_directory(directory): # ディレクトリ内のすべてのファイルとサブディレクトリを取得する for root, dirs, files in os.walk(directory): for file in files: if file.endswith('.html'): file_path = os.path.join(root, file) process_html_file(file_path, directory) # フォルダパスも渡す def process_html_file(file_path, base_directory): try: with open(file_path, 'r', encoding='utf-8') as f: content = f.read() # リンクタグのコードを取得する link_tags = re.findall(r'<a\s+(?:[^>]*?\s+)?href=[\'"]([^"\']+)', content, flags=re.IGNORECASE) for tag in link_tags: # httpやhttpsなどのスキームが省略されたリンクも対象とする if '//' in tag and 'www.example.com' not in tag: folder_name = os.path.relpath(os.path.dirname(file_path), base_directory) # フォルダ名を取得 file_name = os.path.basename(file_path) # 外部リンクとファイル名、フォルダ名の組み合わせを追加 external_links.setdefault(tag, []).append((folder_name, file_name)) except UnicodeDecodeError as e: error_message = f'Error processing {file_path}: {str(e)}' print(error_message) with open('error.txt', 'a', encoding='utf-8') as error_file: error_file.write(f'{error_message}\n') # 指定されたディレクトリ内のHTMLファイルを処理する directory = r'ウェブサイトのフォルダ' external_links = {} process_directory(directory) # 外部リンクとフォルダ名、ファイル名を一覧でlist.txtに出力する(外部リンクの昇順) with open('list.txt', 'w', encoding='utf-8') as f: sorted_links = sorted(external_links.items(), key=lambda x: x[0]) for link, file_info in sorted_links: file_names = [os.path.join(folders, file) for folders, file in file_info] f.write(f'{link}\t{", ".join(file_names)}\n')コピー

外部リンクに加えて、その外部リンクがあるファイル名も「list.txt」に出力されますが、複数のファイル名が該当する場合にはカンマで区切ってます。エラーは「error.txt」に出力されます。
■②外部リンクのステータスコードをチェックして「code.txt」に出力
次に、外部リンクのステータスコードをチェックしてリンク切れがないか確認します。
「list.txt」の内容を確認し、チェックしたくない外部リンクの行は削除した上で実行しましょう。アフィリエイトリンクなどは、場合によってはチェックしない方がよいかもしれません。ユーザーエージェントはアクセスログなどを確認して、一般的なものを使用することをおすすめします。
import requests # ユーザーエージェントの設定 headers = { "User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) CriOS/79.0.3945.73 Mobile/15E148 Safari/604.1" } # list.txtから外部リンクを読み込む with open('list.txt', 'r', encoding='utf-8') as f: lines = f.readlines() # 外部リンクごとにステータスコードを取得し、code.txtに出力する with open('code.txt', 'w', encoding='utf-8') as code_file: for line in lines: if '\t' in line: link, file_names = line.strip().split('\t') try: response = requests.get(link, headers=headers, allow_redirects=False) redirect_url = '' if response.status_code in [301, 302, 303, 307, 308]: redirect_url = response.headers['Location'] code_file.write(f'{link}\t{response.status_code}\t{len(response.content)}\t{redirect_url}\n') except Exception as e: print(f'Error processing {link}: {e}') with open('error.txt', 'a', encoding='utf-8') as error_file: error_file.write(f'{link}\t{str(e)}\n')
結果については、「code.txt」にて出力されます。外部リンク名、ステータスコード、リダイレクト先のURLなどが記載されます。
■③エクセルに貼り付けて並べ替え
出力された「code.txt」の内容を全て選択し、コピペでエクセルに貼り付けて降順で並べ替えます。エラーコードの内容もチェックします。
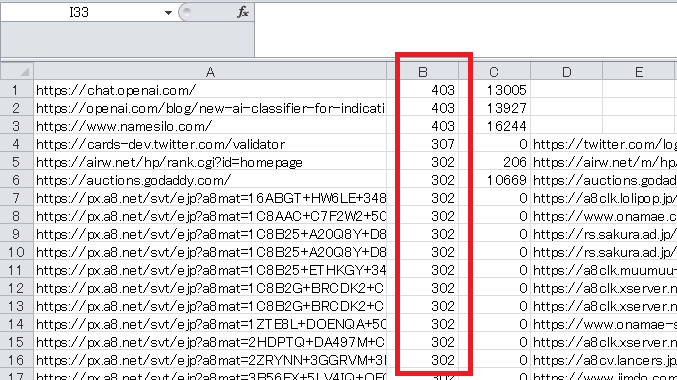
ステータスコードの大きい順に並べ替えて404などを確認し、あるいはサイズが極めて小さいものについては、リンク切れの可能性が高いです。最初の「list.txt」に、外部リンクが掲載されているファイル名が記載されているので、そちらから外部リンクを修正します。
うまく行かない場合には、生成AIにコードを書いてもらうとよいでしょう。